Introduction
This document describes
-
Ticket Creation - how a ticket is created when a user calls the help desk.
-
Ticket Modification - how data is input once a ticket has been created.
-
Ticket Escalation - the process of escalating a ticket (sending the
problem to be handled by a more senior person) using Remedy.
-
User Administration - how Juno maintains the databases where information
about the Remedy users (agents) is stored.
-
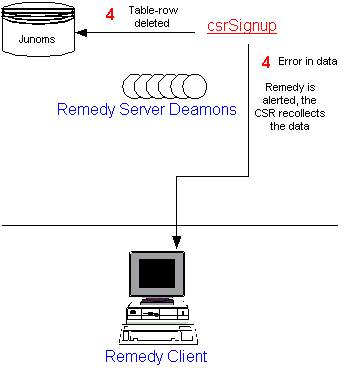
CSR (Customer Service Representative) Signup - what happens when someone calls
a CSR in order to signup for Juno.
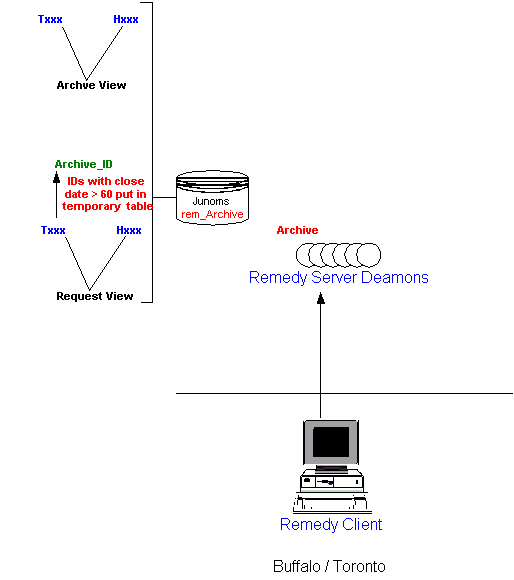
- Archiving - Backing up ticket information.
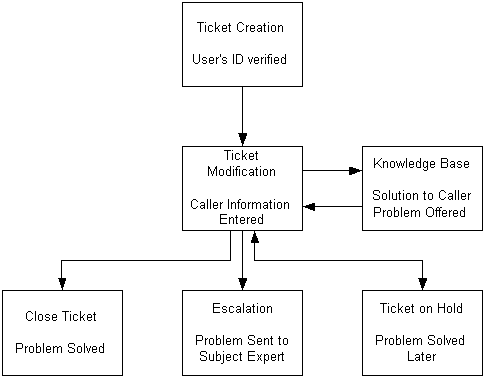
The following diagram and description present how a ticket is created
after a help desk caller's ID is established.
Note: a member's ID is his/her Juno email address. When a non-member phones,
the helpdesk agent uses the caller's
last name, first name and phone number as an identifying ID.
The UBD returns the user's Password, Account Status and Service Level.
This information is stored in the Junoms database. Later, using the user ID as a handle, Remedy requests
all the data received from the UDB.
In the event that the UDB does not return any information,
Remedy concludes that the caller is not a member and sends an appropriate code back the the
Remedy Client.
Note:
The Remedy Client can only receive data from a relational database via
Remedy servers. A program can only return a status code.
As a result, there is no easy way to
get data back to the Remedy Client when one of the server deamons
runs a process that is not a database command.
The Juno solution is to load this data into a ducktape table in the Junoms database, then grab
everything on
the ducktape at the end of the process and bring it back to the Remedy Client.
Once the ticket is created through the Request Schema, the agent fills in the fields to determine the nature of the problem.
If the cannot solve the problem by using the integration of the solution explorer, then they escalate the
ticket.
Establish the type of ticket you're talking about using a dynamic menu.
There are buttons next some of the fields the bring up possible values that can go in the field. That means
these are required fields. If nothing is available, then it is not required (or another field must be
filled in first). Once you've filled in the section, press "Send" to send the information to the
Knowledge Base. This brings up an application Solution Explorer which provides a variet of solutions to the
particular problem. Press "Retieve", brings back the solution with an ID. Bring this information
back tothe ticket in order to record Category type - Subtype coorelation between - what's the solution that
best fits the problem. The poit of
Ticket Status section
Agents who are unable to handle a particular problem can send the ticket to
another agent who does have the ability to handle the problem. This is known as escalation. (Note:
this is different from the Remedy product feature also known as Escalation).
There are a number of ways for an
agent to escalate a ticket using Remedy. These are:
Upon changing the level, the Remedy backend (found in Junoms) checks if the agent
is authorized to escalate to that level. If they agent is not authorized, s/he is
informed that this is not a legal
escalation. If the agent is authorized, the system looks for an agent with
no assigned tickets belonging to the
proper group (Customer Service or Technical Support) and with
the proper skills to handle the problem.
If there are no agents without any tickets assigned to them, the system looks for an agent with the
fewest assigned tickets and the proper category/skills match. In the event that there is
no proper category/skills match, the problem is escalated to the agent with the fewest assigned tickets.
An email confirming the escalation is sent to all agents involved in the escalation.
The following flowchart depicts the different escalation checks performed by Remedy:
User Data Tables
All data about Remedy users (these are Call Center agents and Juno staff(primarily Member Services))
is stored in four tables. Two of these are created
by Remedy itself. The other set has been developed by Juno to help meet its unique needs.
Juno uses data from all of these tables to identify and store information about its Remedy users.
The two Remedy tables are:
The two Juno tables are:
User-skill - This table contains the user name, and skills (what skills they have).
Juno has created proprietary tools for creating and updating the data in these tables.
The tools are available in two different interfaces:
The following diagram provides a visual representation of the Juno User Administration System.
Ticket Creation

Ticket Modification
Account Information section.
Technical Support Ticket:
Customer Support Ticket
Escalation

User Administration
Table Updates
All of these tools run off a common module called User-admin.pm.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}